



Proof of Aliasing Theorem
To show:
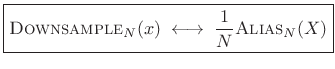
or
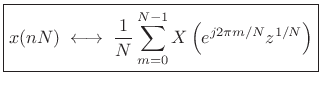
From the DFT case [264], we know this is true when ![]() and
and ![]() are each complex sequences of length
are each complex sequences of length ![]() , in which case
, in which case ![]() and
and ![]() are length
are length ![]() . Thus,
. Thus,
 |
(3.38) |
where we have chosen to keep frequency samples
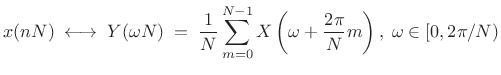 |
(3.39) |
Replacing
Next Section:
Practical Zero Padding
Previous Section:
Real Even (or Odd) Signals







