



Likelihood Function
The likelihood function
![]() is defined as the
probability density function of
is defined as the
probability density function of ![]() given
given
![]() , evaluated at a particular
, evaluated at a particular ![]() , with
, with
![]() regarded as a variable.
regarded as a variable.
In other words, the likelihood function
![]() is just the PDF
of
is just the PDF
of ![]() with a particular value of
with a particular value of ![]() plugged in, and any parameters
in the PDF (mean and variance in this case) are treated as variables.
plugged in, and any parameters
in the PDF (mean and variance in this case) are treated as variables.

For the sinusoidal parameter estimation problem, given a set of
observed data samples ![]() , for
, for
![]() , the likelihood
function is
, the likelihood
function is
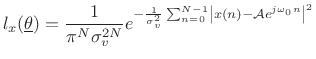 |
(6.50) |
and the log likelihood function is
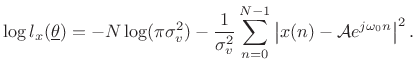 |
(6.51) |
We see that the maximum likelihood estimate for the parameters of a sinusoid in Gaussian white noise is the same as the least squares estimate. That is, given
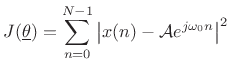 |
(6.52) |
as we saw before in (5.33).
Multiple Sinusoids in Additive Gaussian White Noise
The preceding analysis can be extended to the case of multiple sinusoids in white noise [120]. When the sinusoids are well resolved, i.e., when window-transform side lobes are negligible at the spacings present in the signal, the optimal estimator reduces to finding multiple interpolated peaks in the spectrum.
One exact special case is when the sinusoid frequencies ![]() coincide with the ``DFT frequencies''
coincide with the ``DFT frequencies''
![]() , for
, for
![]() . In this special case, each sinusoidal peak sits
atop a zero crossing in the window transform associated with every
other peak.
. In this special case, each sinusoidal peak sits
atop a zero crossing in the window transform associated with every
other peak.
To enhance the ``isolation'' among multiple sinusoidal peaks, it is natural to use a window function which minimizes side lobes. However, this is not optimal for short data records since valuable data are ``down-weighted'' in the analysis. Fundamentally, there is a trade-off between peak estimation error due to overlapping side lobes and that due to widening the main lobe. In a practical sinusoidal modeling system, not all sinusoidal peaks are recovered from the data--only the ``loudest'' peaks are measured. Therefore, in such systems, it is reasonable to assure (by choice of window) that the side-lobe level is well below the ``cut-off level'' in dB for the sinusoidal peaks. This prevents side lobes from being comparable in magnitude to sinusoidal peaks, while keeping the main lobes narrow as possible.
When multiple sinusoids are close together such that the associated main lobes overlap, the maximum likelihood estimator calls for a nonlinear optimization. Conceptually, one must search over the possible superpositions of the window transform at various relative amplitudes, phases, and spacings, in order to best ``explain'' the observed data.
Since the number of sinusoids present is usually not known, the number can be estimated by means of hypothesis testing in a Bayesian framework [21]. The ``null hypothesis'' can be ``no sinusoids,'' meaning ``just white noise.''
Non-White Noise
The noise process ![]() in (5.44) does not have to be white
[120]. In the non-white case, the spectral shape of the noise
needs to be estimated and ``divided out'' of the spectrum. That is, a
``pre-whitening filter'' needs to be constructed and applied to the
data, so that the noise is made white. Then the previous case can be
applied.
in (5.44) does not have to be white
[120]. In the non-white case, the spectral shape of the noise
needs to be estimated and ``divided out'' of the spectrum. That is, a
``pre-whitening filter'' needs to be constructed and applied to the
data, so that the noise is made white. Then the previous case can be
applied.
Next Section:
Generality of Maximum Likelihood Least Squares
Previous Section:
Maximum Likelihood Sinusoid Estimation







