



Time-Varying Delay-Line Reads
If ![]() denotes the input to a time-varying delay, the output can be
written as
denotes the input to a time-varying delay, the output can be
written as
Let's analyze the frequency shift caused by a time-varying delay by
setting ![]() to a complex sinusoid at frequency
to a complex sinusoid at frequency ![]() :
:
where
Comparing Eq.![]() (5.6) to Eq.
(5.6) to Eq.![]() (5.2), we find that the
time-varying delay most naturally simulates Doppler shift caused by a
moving listener, with
(5.2), we find that the
time-varying delay most naturally simulates Doppler shift caused by a
moving listener, with
That is, the delay growth-rate,
Simulating source motion is also possible, but the relation
between delay change and desired frequency shift is more complex, viz.,
from Eq.![]() (5.2) and Eq.
(5.2) and Eq.![]() (5.6),
(5.6),
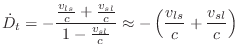
The time-varying delay line was described in §5.1. As discussed there, to implement a continuously varying delay, we add a ``delay growth parameter'' g to the delayline function in Fig.5.1, and change the line
rptr += 1; // pointer updateto
rptr += 1 - g; // pointer updateWhen g is 0, we have a fixed delay line, corresponding to
Note that when the read- and write-pointers are driven directly from a model of physical propagation-path geometry, they are always separated by predictable minimum and maximum delay intervals. This implies it is unnecessary to worry about the read-pointer passing the write-pointers or vice versa. In generic frequency shifters [275], or in a Doppler simulator not driven by a changing geometry, a pointer cross-fade scheme may be necessary when the read- and write-pointers get too close to each other.
Next Section:
Multiple Read Pointers
Previous Section:
Doppler Simulation via Delay Lines







