



Random Variables & Stochastic Processes
For a full treatment of random variables and stochastic processes (sequences of random variables), see, e.g., [201]. For practical every-day signal analysis, the simplified definitions and examples below will suffice for our purposes.
Probability Distribution
Definition:
A probability distribution
![]() may be defined as a
non-negative real function of all possible outcomes of some random
event. The sum of the probabilities of all possible outcomes is
defined as 1, and probabilities can never be negative.
may be defined as a
non-negative real function of all possible outcomes of some random
event. The sum of the probabilities of all possible outcomes is
defined as 1, and probabilities can never be negative.
Example:
A coin toss has two outcomes, ``heads'' (H) or ``tails'' (T),
which are equally likely if the coin is ``fair''. In this case, the
probability distribution is
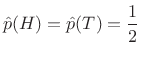 |
(C.1) |
where
Independent Events
Two probabilistic events
![]() and
and ![]() are said to be
independent if the probability of
are said to be
independent if the probability of
![]() and
and ![]() occurring together equals the
product of the probabilities of
occurring together equals the
product of the probabilities of
![]() and
and ![]() individually, i.e.,
individually, i.e.,
| (C.2) |
where
Example:
Successive coin tosses are normally independent.
Therefore, the probability of getting heads twice in a row is
given by
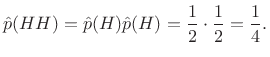 |
(C.3) |
Random Variable
Definition:
A random variable ![]() is defined as a real- or complex-valued
function of some random event, and is fully characterized by its
probability distribution.
is defined as a real- or complex-valued
function of some random event, and is fully characterized by its
probability distribution.
Example:
A random variable can be defined based on a coin toss by defining
numerical values for heads and tails. For example, we may assign 0 to
tails and 1 to heads. The probability distribution for this random
variable is then
![$\displaystyle \hat{p}(x) = \left\{\begin{array}{ll} \frac{1}{2}, & x = 0 \\ [5pt] \frac{1}{2}, & x = 1 \\ [5pt] 0, & \mbox{otherwise}. \\ \end{array} \right. \protect$](http://www.dsprelated.com/josimages_new/sasp2/img2624.png)
Example:
A die can be used to generate integer-valued random variables
between 1 and 6. Rolling the die provides an underlying random event.
The probability distribution of a fair die is the
discrete uniform distribution between 1 and 6. I.e.,
![$\displaystyle \hat{p}(x) = \left\{\begin{array}{ll} \frac{1}{6}, & x = 1,2,\ldots,6 \\ [5pt] 0, & \mbox{otherwise}. \\ \end{array} \right.$](http://www.dsprelated.com/josimages_new/sasp2/img2625.png) |
(C.5) |
Example:
A pair of dice can be used to generate integer-valued random
variables between 2 and 12. Rolling the dice provides an underlying
random event. The probability distribution of two fair dice is given by
![$\displaystyle \hat{p}(x) = \left\{\begin{array}{ll} \frac{x-1}{36}, & x = 2,3,\ldots,7 \\ [5pt] \frac{13-x}{36}, & x = 7,8,\ldots,12 \\ [5pt] 0, & \mbox{otherwise}. \\ \end{array} \right.$](http://www.dsprelated.com/josimages_new/sasp2/img2626.png) |
(C.6) |
This may be called a discrete triangular distribution. It can be shown to be given by the convolution of the discrete uniform distribution for one die with itself. This is a general fact for sums of random variables (the distribution of the sum equals the convolution of the component distributions).
Example:
Consider a random experiment in which a sewing needle is dropped onto
the ground from a high altitude. For each such event, the angle of
the needle with respect to north is measured. A reasonable model for
the distribution of angles (neglecting the earth's magnetic field) is
the continuous uniform distribution on ![]() , i.e., for
any real numbers
, i.e., for
any real numbers ![]() and
and ![]() in the interval
in the interval ![]() , with
, with ![]() , the probability of the needle angle falling within that interval
is
, the probability of the needle angle falling within that interval
is
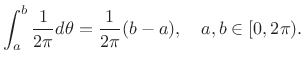 |
(C.7) |
Note, however, that the probability of any single angle
![$\displaystyle p(\theta) = \left\{\begin{array}{ll} \frac{1}{2\pi}, & 0\leq \theta < 2\pi \\ [5pt] 0, & \mbox{otherwise}. \\ \end{array} \right.$](http://www.dsprelated.com/josimages_new/sasp2/img2631.png) |
(C.8) |
To calculate a probability, the PDF must be integrated over one or more intervals. As follows from Lebesgue integration theory (``measure theory''), the probability of any countably infinite set of discrete points is zero when the PDF is finite. This is because such a set of points is a ``set of measure zero'' under integration. Note that we write
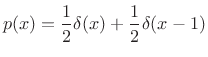 |
(C.9) |
where
Stochastic Process
(Again, for a more complete treatment, see [201] or the like.)
Definition:
A stochastic process ![]() is defined as a sequence of random
variables
is defined as a sequence of random
variables ![]() ,
,
![]() .
.
A stochastic process may also be called a random process, noise process, or simply signal (when the context is understood to exclude deterministic components).
Stationary Stochastic Process
Definition:
We define a stationary stochastic process ![]() ,
,
![]() as a stochastic process consisting of
identically distributed random variables
as a stochastic process consisting of
identically distributed random variables ![]() . In
particular, all statistical measures are time-invariant.
. In
particular, all statistical measures are time-invariant.
When a stochastic process is stationary, we may measure statistical features by averaging over time. Examples below include the sample mean and sample variance.
Expected Value
Definition:
The expected value of a continuous random variable
![]() is denoted
is denoted ![]() and is defined by
and is defined by
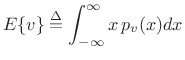 |
(C.12) |
where
Example:
Let the random variable ![]() be uniformly distributed between
be uniformly distributed between
![]() and
and ![]() , i.e.,
, i.e.,
![$\displaystyle p_v(x) = \left\{\begin{array}{ll} \frac{1}{b-a}, & a\leq x \leq b \\ [5pt] 0, & \hbox{otherwise}. \\ \end{array} \right.$](http://www.dsprelated.com/josimages_new/sasp2/img2645.png) |
(C.13) |
Then the expected value of
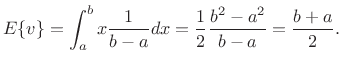 |
(C.14) |
Thus, the expected value of a random variable uniformly distributed between
For a stochastic process, which is simply a sequence of random
variables, ![]() means the expected value of
means the expected value of ![]() over
``all realizations'' of the random process
over
``all realizations'' of the random process ![]() . This is also
called an ensemble average. In other words, for each ``roll of
the dice,'' we obtain an entire signal
. This is also
called an ensemble average. In other words, for each ``roll of
the dice,'' we obtain an entire signal
![]() , and to compute
, and to compute ![]() , say, we average
together all of the values of
, say, we average
together all of the values of ![]() obtained for all ``dice rolls.''
obtained for all ``dice rolls.''
For a stationary random process
![]() , the random variables
, the random variables ![]() which make it up
are identically distributed. As a result, we may normally compute
expected values by averaging over time within a single
realization of the random process, instead of having to average
``vertically'' at a single time instant over many realizations of the
random process.C.2 Denote time averaging by
which make it up
are identically distributed. As a result, we may normally compute
expected values by averaging over time within a single
realization of the random process, instead of having to average
``vertically'' at a single time instant over many realizations of the
random process.C.2 Denote time averaging by
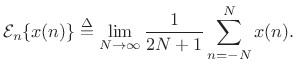 |
(C.15) |
Then, for a stationary random processes, we have
We are concerned only with stationary stochastic processes in this book. While the statistics of noise-like signals must be allowed to evolve over time in high quality spectral models, we may require essentially time-invariant statistics within a single frame of data in the time domain. In practice, we choose our spectrum analysis window short enough to impose this. For audio work, 20 ms is a typical choice for a frequency-independent frame length.C.3 In a multiresolution system, in which the frame length can vary across frequency bands, several periods of the band center-frequency is a reasonable choice. As discussed in §5.5.2, the minimum number of periods required under the window for resolution of spectral peaks depends on the window type used.
Mean
Definition:
The mean of a stochastic process ![]() at time
at time ![]() is defined as
the expected value of
is defined as
the expected value of ![]() :
:
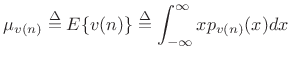 |
(C.16) |
where
For a stationary stochastic process ![]() , the mean is given by
the expected value of
, the mean is given by
the expected value of ![]() for any
for any ![]() . I.e.,
. I.e.,
![]() for all
for all ![]() .
.
Sample Mean
Definition:
The sample mean of a set of ![]() samples from a particular
realization of a stationary stochastic process
samples from a particular
realization of a stationary stochastic process ![]() is defined
as the average of those samples:
is defined
as the average of those samples:
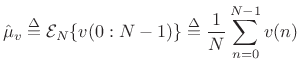 |
(C.17) |
For a stationary stochastic process
| (C.18) |
Variance
Definition:
The variance or second central moment of a stochastic
process ![]() at time
at time ![]() is defined as the expected value of
is defined as the expected value of
![]() :
:
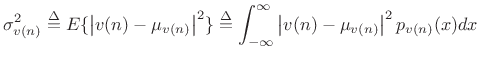 |
(C.19) |
where
For a stationary stochastic process ![]() , the variance is given
by the expected value of
, the variance is given
by the expected value of
![]() for any
for any ![]() .
.
Sample Variance
Definition:
The sample variance of a set of ![]() samples from a particular
realization of a stationary stochastic process
samples from a particular
realization of a stationary stochastic process ![]() is defined
as average squared magnitude after removing the known mean:
is defined
as average squared magnitude after removing the known mean:
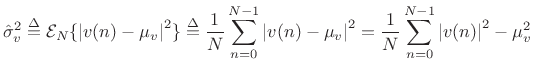 |
(C.20) |
The sample variance is a unbiased estimator of the true variance when the mean is known, i.e.,
| (C.21) |
This is easy to show by taking the expected value:
When the mean is unknown, the sample mean is used in its place:
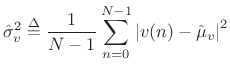 |
(C.23) |
The normalization by
Next Section:
Correlation Analysis
Previous Section:
Relation of Smoothness to Roll-Off Rate






