



Understanding and Implementing the Sliding DFT
Introduction
In many applications the detection or processing of signals in the frequency domain offers an advantage over performing the same task in the time-domain. Sometimes the advantage is just a simpler or more conceptually straightforward algorithm, and often the largest barrier to working in the frequency domain is the complexity or latency involved in the Fast Fourier Transform computation. If the frequency-domain data must be updated frequently in a real-time application, the complexity and latency of the FFT can become a significant impediment to achieving system goals and keeping cost and power consumption low. Many modern applications, like medical imaging, radar, touch-screen sensing, and communication systems, use frequency-domain algorithms for detecting and processing signals. In many implementations complexity or power consumption must be kept low while minimizing latency. The Sliding DFT algorithm provides frequency domain updates on a per-sample basis with significantly fewer computations than the FFT for each update.
First, The Math
The derivation of the Sliding DFT is reasonably straightforward and shows exact equivalence to the DFT, i.e., there is no loss of information or distortion tradeoff with the Sliding DFT algorithm compared to a traditional DFT or FFT. The derivation is shown here for completeness, but disinterested readers can skip this section and not lose too much sleep.
The basic assumption for using a Sliding DFT is that a long time-domain stream exists over which a shorter transform window will be slid. This is essentially what happens with a spectrogram, where a length-N transform is taken at regular intervals in a long or continuous stream of time-domain samples. For the derivation of the Sliding DFT we assume that a transform is taken with every new time-domain sample, so that the length-N transform window moves along the time domain stream a sample at a time. The input stream with samples xk, where k runs over an index with a range larger than N, can then yield a length-N transform at every kth sample. Using the traditional definition of the DFT we can write this kth transform as follows, where f is the frequency index and n the time index within the length-N transform window:
Eq. 1

The next transform in the sliding sequence will be the (k+1)th and can be rewritten as:
Eq. 2
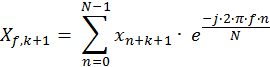
A simple trick can now be done which allows a rearrangement of the terms. We can substitute p = n+1 into Eq. 2, with the range of p therefore 1 to N, instead of 0 to N-1 for n. The computations are the same as before, just with a different index definition.
Eq. 3
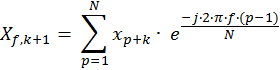
The Nth term can be taken out of the summation and added separately. At the same time we can introduce a zeroth term in the summation, as long as we subtract it again outside of the summation. The resulting equation is inelegant, but useful:
Eq. 4
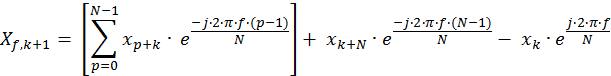
The common term can be factored out as follows:
Eq. 5
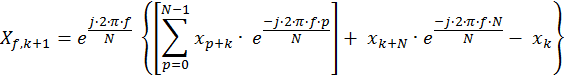
In Eq. 5 the exponential with the xk+N term can never have a value other than 1+j0 since f always has integer values, and so can be eliminated. The summation, in the square brackets, is the DFT of the kth vector with p as an index instead of n. Equation 5 can therefore be rewritten as:
Eq. 6
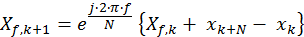
The Algorithm
Equation 6 shows the derived expression for the Sliding DFT. The frequency bins of the (k+1)th transform, Xf,k+1, are computed recursively from the bins of the kth transform Xf,k. For each desired frequency bin with index f, the difference of the newest time-domain input sample, xk+N, and the oldest sample in the DFT window, xk, is added to the bin. The result is then multiplied by the bin-frequency-dependent exponential term, e-j2pf/N, to produce the updated output for that bin.
The advantages compared to using an FFT are readily apparent. For each transform the update requires one complex addition, xk+N - xk, that is common to all bins, and one complex multiplication and addition for each output bin. If the input stream, x, is real-valued, then only the initial addition is real-valued. Only the desired output bins need to be computed since there is no interdependence between bins, and the transform window can be any length N rather than only powers of two. Compare this to log2(N) stages of N/2 butterfly operations for an FFT, where essentially all of the N outputs must be computed regardless of how many are actually needed. Figure 1 shows a signal flow diagram of an implementation of Equation 6. The initial delay and addition is common to all bins, and the recursive complex multiply and accumulation stage is repeated for each frequency bin to be computed.
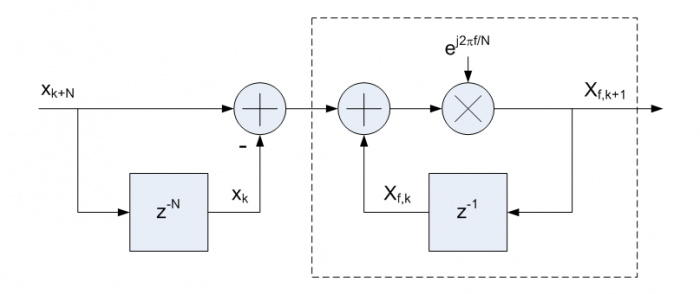
Figure 1. Signal flow diagram of the Sliding DFT as expressed in Equation 6. The boxed portion is repeated for each unique value of f.
The computational advantage of the Sliding DFT may diminish if a new transform is not needed with every input sample, e.g., if a transform is only needed every M input samples, and all output bins are computed, the computation order would be O(N×M) rather than O(N×log2(N)) for the FFT. The Sliding DFT will still provide an advantage in latency in all cases, however, since after the Mth input each output bin can be computed with only two complex-valued operations once xk+N - xk is computed.
Initialization
The recursive nature of the Sliding DFT algorithm means that some initialization method is required. The output Xf,k+1 is only valid if Xf,k was valid, and each output relies on inputs from N previous samples. There are two common methods for initializing the algorithm:
1. Cycle zeroes in to flush the delay lines before cycling in data. Similarly, if the buffer registers are resettable, resetting the signal path memory to zero before cycling data in accomplishes the same thing. After N data samples have been cycled in the output will be valid.
2. The N cycle initialization delay in the first method can be avoided by initializing all Xf,k with an FFT of the previous N input samples. In some systems, especially off-line applications, this may provide an advantage.
Numeric Stability
In applications where the computations are performed with integer or fixed-point arithmetic, truncation or rounding of the e-j2pf/N coefficients can result in a complex coefficient magnitude greater than unity. In these cases the corresponding Xf,k output may become unstable and experience growth from self-excitation. Usually a simple fix for this condition is to subtract an LSB from the largest component, either I or Q, of the offending coefficient which should bring the coefficient magnitude back to less than or equal to unity.
Conclusion
Under certain common circumstances the Sliding DFT provides computational and latency advantages over the FFT with no loss of information or added distortion. The computational advantage can be significant, providing a reduction in complexity and/or power consumption when compared to the use of an FFT. Similarly, in real-time applications the reduction in latency can be critical to system performance.
References
[1] T. Springer. "Sliding FFT computes frequency spectra in real time", EDN Magazine, Sept. 29, 1988, pp. 161-170.
[2] E. Jacobsen and R. Lyons. "The Sliding DFT", IEEE Signal Processing Magazine, Mar. 2003, pp. 74-80.
[3] E. Jacobsen and R. Lyons. "An update to the Sliding DFT", IEEE Signal Processing Magazine, Jan. 2004, pp. 110-111.
[4] E. Jacobsen and R. Lyons, "Sliding Spectrum Analysis," Ch. 14 in Streamlining Digital Signal Processing: A Tricks of the Trade Guidebook (Paperback), Richard G. Lyons (Editor), Wiley-IEEE Press, 2007, pp. 145-157
[5] Richard S. Lyons, Understanding Digital Signal Processing, Prentice-Hall, 3rd Ed., 2010
- Comments
- Write a Comment Select to add a comment

Thank you for sharing. Sliding DFT also has spectrum leakage. I have seen some operations that add windows in the frequency domain, but these window functions are all cosine windows. How do I add Kaiser window to the sliding DFT, or in the time domain? How to add windows
If I understand this correctly from the rather quick perusal I currently have time to give it, this technique reduces the per-sample calculation from O(n*log(n)) to O(log(n)). Is that correct?
If so, is there any C implementation of the initialization and the recursive step available? My DSP interest has been re-awakened by the emergence of the Raspberry Pi 3 which just might be suitable for my long standing but long dormant interest in practical and inexpensive real time convolution for audio using 1k-4k length kernels. The time might finally be at hand where that work deserves more attention.
I've developed measurement and fast convolution based implementation techniques which allow me to quite effectively emulate the sound of any given headphone/earphone/canalphone with any other such device within the limitations of linearity (which modern magnet materials have drastically improved even on very inexpensive 'phones.) I've developed this for PC application and it works but is kludgy, requires the use of some other proprietary software, and is not terribly practical for general use. The thought of making it more generally available via a Raspberry Pi 3 package tickles me pink.

The per-sample output computation, once the system is initialized, drops from O(n*log(n)) to O(n). The drastic difference is due to the sliding DFT re-using the previous inputs, but the FFT starts from scratch each time.
A question about zero padded signals. Is it also possible to do sliding dft if the signal is zero padded?
For example if you have a signal [1, 2, 3, 4, 0 ,0 ,0, 0], how to calculate dft of the signal [2, 3, 4, 5, 0, 0, 0, 0]?
Isn't this algorithm wrong? Don't you need to rotate the frequency bins before adding in the new data and subtracting the old data? As a simple example image you initialize to all zeros in your fft. Then you slide in a 1. The new fft should be all zeros rotated = zeros and then add in a 1 and subtract a 0.
With this algorithm and the order of operations above you get the 1 rotated across all of the bins. An incorrect result. What am i missing?
Sorry for the very late reply, I only just now saw your question. In case it's still relevant, I'll respond below.
For your example case, the output starting from an all-zero output and sliding in a single 1 will provide the output for an input vector with all zeros with a 1 on the end. For a data input sequence, the output will be valid on the input data after N samples have been cycled in, and thereafter as each new sample is cycled in and the oldest subtracted out.
I hope that makes sense.
Yeah, those were my thoughts after reading this... "where's the subtraction of the [going out of left side] sample?"
In Eq. 6 it's the -x(k).
Hi,
Thanks a lot for this eye-opening post, really! BUT…
I have further investigated the references and implemented the algorithms myself. I am sharing a 'ready to run' Matlab demonstration for those interested.
I have come to three conclusions and I sincerely hope somebody can help me change my mind:
- The sDFT, as depicted in this post has serious convergency issues even for double precission platforms. Following [4], a way for damping it is presented. This however introduces a big error in the estimated magnitudes.
- A solution to this is presented in [4], Ch.21. It is called the modulated sliding DFT of msDFT. I have endeavoured to implement it and I still experience convergency issues so I guess either my implementation is flawed or the alternative is no good.
- The left part of figure 1 in the post is a comb filter. If there is frequency content in the signal to be analysed at the frequency of the notches (i.e. @ integer multiples of fs/N), those won't be detected by the sliding DFT.
Please prove me wrong!
LINKS below:
- Matlab demonstration of sDFT and msDFT. Set the variable 'choice' to 0/1 to use one or the other.
- Annotated figure to follow for understanding my implementation of msDFT.
Thanks
Gerardo
Stability in recursive digital computations, for filters or transforms, is a well-studied topic. There is a wealth of literature in texts and papers beyond those cited above.
What is the exact magnitude of the coefficients in bins that are experiencing instability?
Hey,
I am sliding a 2^10 point DFT over 100s of a signal sampled at 0.016s. My bins of interest are between 5 and 30Hz and the resolution I get is around 0.06Hz. The test signal contains freqs. spaced by 1Hz up to 20Hz, each of them of amplitude 1.
Using sDFT 'as is', without any damping factor results in all those frequencies being detected with changing amplitudes between 0 and 2.
Adding damping to the sDFT calms a bit the oscillations. This is achieved as per [4] changing 'd' from 1 to i.e. 0.999.
Using the modulated version of the algorithm ('creme de la creme') does not significantly improve anything.
Any hints what may be wrong here?
Thanks!
PD. I humbly believe the Matlab script is compact and illustrative for proving these points. The sDFT is merely 4 lines of code and the msDFT just 8. Both are implemented as functions at the end of the script. I am glad to share the code and encourage interested readers to give it a try and find out if anything might be wrong or missing.
To post reply to a comment, click on the 'reply' button attached to each comment. To post a new comment (not a reply to a comment) check out the 'Write a Comment' tab at the top of the comments.
Please login (on the right) if you already have an account on this platform.
Otherwise, please use this form to register (free) an join one of the largest online community for Electrical/Embedded/DSP/FPGA/ML engineers:





