



Formant Filtering Example
In speech synthesis [27,39], digital filters are often used to simulate formant filtering by the vocal tract. It is well known [23] that the different vowel sounds of speech can be simulated by passing a ``buzz source'' through a only two or three formant filters. As a result, speech is fully intelligible through the telephone bandwidth (nominally only 200-3200 Hz).
A formant is a resonance in the voice spectrum. A
single formant may thus be modeled using one biquad
(second-order filter section). For example, in the vowel ![]() as in
``father,'' the first three formant center-frequencies have been
measured near 700, 1220, and 2600 Hz, with half-power
bandwidths10.7 130, 70, and 160 Hz [40].
as in
``father,'' the first three formant center-frequencies have been
measured near 700, 1220, and 2600 Hz, with half-power
bandwidths10.7 130, 70, and 160 Hz [40].
In principle, the formant filter sections are in series, as can be found by deriving the transfer function of an acoustic tube [48]. As a consequence, the vocal-tract transfer function is an all-pole filter (provided that the nasal tract is closed off or negligible). As a result, there is no need to specify gains for the formant resonators--only center-frequency and bandwidth are necessary to specify each formant, leaving only an overall scale factor unspecified in a cascade (series) formant filter bank.
Numerically, however, it makes more sense to implement disjoint resonances in parallel rather than in series.10.8 This is because when one formant filter is resonating, the others will be attenuating, so that to achieve a particular peak-gain at resonance, the resonating filter must overcome all combined attenuations as well as applying its own gain. In fixed-point arithmetic, this can result in large quantization-noise gains, especially for the last resonator in the chain. As a result of these considerations, our example will implement the formant sections in parallel. This means we must find the appropriate biquad numerators so that when added together, the overall transfer-function numerator is a constant. This will be accomplished using the partial fraction expansion (§6.8).10.9
The matlab below illustrates the construction of a parallel formant
filter bank for simulating the vowel ![]() . For completeness, it is
used to filter a bandlimited impulse train, in order to synthesize the
vowel sound.
. For completeness, it is
used to filter a bandlimited impulse train, in order to synthesize the
vowel sound.
F = [700, 1220, 2600]; % Formant frequencies (Hz) BW = [130, 70, 160]; % Formant bandwidths (Hz) fs = 8192; % Sampling rate (Hz) nsecs = length(F); R = exp(-pi*BW/fs); % Pole radii theta = 2*pi*F/fs; % Pole angles poles = R .* exp(j*theta); % Complex poles B = 1; A = real(poly([poles,conj(poles)])); % freqz(B,A); % View frequency response: % Convert to parallel complex one-poles (PFE): [r,p,f] = residuez(B,A); As = zeros(nsecs,3); Bs = zeros(nsecs,3); % complex-conjugate pairs are adjacent in r and p: for i=1:2:2*nsecs k = 1+(i-1)/2; Bs(k,:) = [r(i)+r(i+1), -(r(i)*p(i+1)+r(i+1)*p(i)), 0]; As(k,:) = [1, -(p(i)+p(i+1)), p(i)*p(i+1)]; end sos = [Bs,As]; % standard second-order-section form iperr = norm(imag(sos))/norm(sos); % make sure sos is ~real disp(sprintf('||imag(sos)||/||sos|| = %g',iperr)); % 1.6e-16 sos = real(sos) % and make it exactly real % Reconstruct original numerator and denominator as a check: [Bh,Ah] = psos2tf(sos); % parallel sos to transfer function % psos2tf appears in the matlab-utilities appendix disp(sprintf('||A-Ah|| = %g',norm(A-Ah))); % 5.77423e-15 % Bh has trailing epsilons, so we'll zero-pad B: disp(sprintf('||B-Bh|| = %g',... norm([B,zeros(1,length(Bh)-length(B))] - Bh))); % 1.25116e-15 % Plot overlay and sum of all three % resonator amplitude responses: nfft=512; H = zeros(nsecs+1,nfft); for i=1:nsecs [Hiw,w] = freqz(Bs(i,:),As(i,:)); H(1+i,:) = Hiw(:).'; end H(1,:) = sum(H(2:nsecs+1,:)); ttl = 'Amplitude Response'; xlab = 'Frequency (Hz)'; ylab = 'Magnitude (dB)'; sym = ''; lgnd = {'sum','sec 1','sec 2', 'sec 3'}; np=nfft/2; % Only plot for positive frequencies wp = w(1:np); Hp=H(:,1:np); figure(1); clf; myplot(wp,20*log10(abs(Hp)),sym,ttl,xlab,ylab,1,lgnd); disp('PAUSING'); pause; saveplot('../eps/lpcexovl.eps'); % Now synthesize the vowel [a]: nsamps = 256; f0 = 200; % Pitch in Hz w0T = 2*pi*f0/fs; % radians per sample nharm = floor((fs/2)/f0); % number of harmonics sig = zeros(1,nsamps); n = 0:(nsamps-1); % Synthesize bandlimited impulse train for i=1:nharm, sig = sig + cos(i*w0T*n); end; sig = sig/max(sig); speech = filter(1,A,sig); soundsc([sig,speech]); % hear buzz, then 'ah'
Notes:
- The sampling rate was chosen to
be
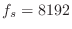 Hz because that is the default Matlab sampling rate,
and because that is a typical value used for ``telephone quality''
speech synthesis.
Hz because that is the default Matlab sampling rate,
and because that is a typical value used for ``telephone quality''
speech synthesis.
- The psos2tf utility is listed in §J.7.
- The overlay of the amplitude responses are shown in Fig.9.6.
![\includegraphics[width=\twidth]{eps/lpcexovl}](http://www.dsprelated.com/josimages_new/filters/img1163.png)
Next Section:
Butterworth Lowpass Filter Example
Previous Section:
Parallel First and/or Second-Order Sections







