



Spectral Envelope Extraction
There are many definitions of spectral envelope. Piecewise-linear (or polynomial spline) spectral envelopes (applied to the spectral magnitude of an STFT frame), have been used successfully in sines+noise modeling of audio signals (introduced in §10.4). Here we will consider spectral envelopes defined by the following two methods for computing them:
- cepstral windowing to lowpass-filter the log-magnitude
spectrum (a ``nonparametric method'')
- using linear prediction (a ``parametric method'') to capture spectral shape in the amplitude-response of an all-pole filter in a source-filter decomposition of the signal (where the source signal is defined to be spectrally flat)
In the following,
![]() denotes the
denotes the ![]() th spectral frame of
the STFT (§7.1), and
th spectral frame of
the STFT (§7.1), and
![]() denotes the spectral
envelope of
denotes the spectral
envelope of
![]() .
.
Cepstral Windowing
The spectral envelope obtained by cepstral windowing is defined as
![$\displaystyle Y_m \eqsp \hbox{\sc DFT}[w \cdot \underbrace{\hbox{\sc DFT}^{-1}\log(\vert X_m\vert)}_{\hbox{real cepstrum}}]$](http://www.dsprelated.com/josimages_new/sasp2/img1728.png) |
(11.2) |
where
![$\displaystyle w(n) \eqsp \left\{\begin{array}{ll} 1, & \vert n\vert< n_c \\ [5pt] 0.5, & \vert n\vert=n_c \\ [5pt] 0, & \vert n\vert>n_c, \\ \end{array} \right.$](http://www.dsprelated.com/josimages_new/sasp2/img1729.png) |
(11.3) |
where
The log-magnitude spectrum of ![]() is thus lowpass filtered
(the real cepstrum of
is thus lowpass filtered
(the real cepstrum of ![]() is ``liftered'') to obtain a smooth spectral
envelope. For periodic signals,
is ``liftered'') to obtain a smooth spectral
envelope. For periodic signals, ![]() should be set below the period
in samples.
should be set below the period
in samples.
Cepstral coefficients are typically used in speech recognition to characterize spectral envelopes, capturing primarily the formants (spectral resonances) of speech [227]. In audio applications, a warped frequency axis, such as the ERB scale (Appendix E), Bark scale, or Mel frequency scale is typically preferred. Mel Frequency Cepstral Coefficients (MFCC) appear to remain quite standard in speech-recognition front ends, and they are often used to characterize steady-state spectral timbre in Music Information Retrieval (MIR) applications.
Linear Prediction Spectral Envelope
Linear Prediction (LP) implicitly computes a spectral envelope that is well adapted for audio work, provided the order of the predictor is appropriately chosen. Due to the error minimized by LP, spectral peaks are emphasized in the envelope, as they are in the auditory system. (The peak-emphasis of LP is quantified in (10.10) below.)
The term ``linear prediction'' refers to the process of predicting a
signal sample ![]() based on
based on ![]() past samples:
past samples:
We call
Taking the z transform of (10.4) yields
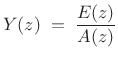 |
(11.5) |
where
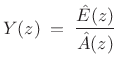 |
(11.6) |
where
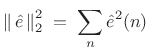 |
(11.7) |
over some range of
If the prediction-error is successfully whitened, then the signal model can be expressed in the frequency domain as
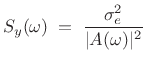 |
(11.8) |
where
| EnvelopeLPC |
(11.9) |
Linear Prediction is Peak Sensitive
By Rayleigh's energy theorem,
![]() (as
shown in §2.3.8). Therefore,
(as
shown in §2.3.8). Therefore,
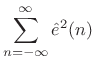
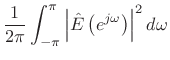
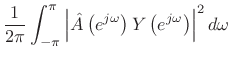
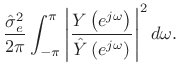
From this ``ratio error'' expression in the frequency domain, we can see that contributions to the error are smallest when
Linear Prediction Methods
The two classic methods for linear prediction are called the autocorrelation method and the covariance method [162,157]. Both methods solve the linear normal equations (defined below) using different autocorrelation estimates.
In the autocorrelation method of linear prediction, the covariance
matrix is constructed from the usual Bartlett-window-biased sample
autocorrelation function (see Chapter 6), and it has the
desirable property that
![]() is always minimum phase (i.e.,
is always minimum phase (i.e.,
![]() is guaranteed to be stable). However, the autocorrelation
method tends to overestimate formant bandwidths; in other words, the
filter model is typically overdamped. This can be attributed to
implicitly ``predicting zero'' outside of the signal frame, resulting
in the Bartlett-window bias in the sample autocorrelation.
is guaranteed to be stable). However, the autocorrelation
method tends to overestimate formant bandwidths; in other words, the
filter model is typically overdamped. This can be attributed to
implicitly ``predicting zero'' outside of the signal frame, resulting
in the Bartlett-window bias in the sample autocorrelation.
The covariance method of LP is based on an unbiased
autocorrelation estimate (see Eq.![]() (6.4)). As a result, it
gives more accurate bandwidths, but it does not guarantee stability.
(6.4)). As a result, it
gives more accurate bandwidths, but it does not guarantee stability.
So-called covariance lattice methods and Burg's method were developed to maintain guaranteed stability while giving accuracy comparable to the covariance method of LP [157].
Computation of Linear Prediction Coefficients
In the autocorrelation method of linear prediction, the linear
prediction coefficients
![]() are computed from the
Bartlett-window-biased autocorrelation function
(Chapter 6):
are computed from the
Bartlett-window-biased autocorrelation function
(Chapter 6):
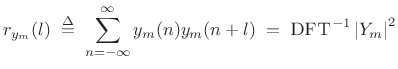
where
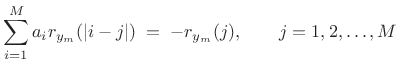
In matlab syntax, the solution is given by ``
If the rank of the ![]() autocorrelation matrix
autocorrelation matrix
![]() is
is ![]() , then the solution to (10.12)
is unique, and
this solution is always minimum phase [162] (i.e., all roots of
, then the solution to (10.12)
is unique, and
this solution is always minimum phase [162] (i.e., all roots of
![]() are inside the unit circle in the
are inside the unit circle in the ![]() plane [263], so
that
plane [263], so
that ![]() is always a stable all-pole filter). In
practice, the rank of
is always a stable all-pole filter). In
practice, the rank of ![]() is
is ![]() (with probability 1) whenever
(with probability 1) whenever ![]() includes a noise component. In the noiseless case, if
includes a noise component. In the noiseless case, if ![]() is a sum
of sinusoids, each (real) sinusoid at distinct frequency
is a sum
of sinusoids, each (real) sinusoid at distinct frequency
![]() adds 2 to the rank. A dc component, or a component at half the
sampling rate, adds 1 to the rank of
adds 2 to the rank. A dc component, or a component at half the
sampling rate, adds 1 to the rank of ![]() .
.
The choice of time window for forming a short-time sample
autocorrelation and its weighting also affect the rank of
![]() . Equation (10.11) applied to a finite-duration frame yields what is
called the autocorrelation method of linear
prediction [162]. Dividing out the Bartlett-window bias in such a
sample autocorrelation yields a result closer to the covariance method
of LP. A matlab example is given in §10.3.3 below.
. Equation (10.11) applied to a finite-duration frame yields what is
called the autocorrelation method of linear
prediction [162]. Dividing out the Bartlett-window bias in such a
sample autocorrelation yields a result closer to the covariance method
of LP. A matlab example is given in §10.3.3 below.
The classic covariance method computes an unbiased sample covariance
matrix by limiting the summation in (10.11) to a range over which
![]() stays within the frame--a so-called ``unwindowed'' method.
The autocorrelation method sums over the whole frame and replaces
stays within the frame--a so-called ``unwindowed'' method.
The autocorrelation method sums over the whole frame and replaces
![]() by zero when
by zero when ![]() points outside the frame--a so-called
``windowed'' method (windowed by the rectangular window).
points outside the frame--a so-called
``windowed'' method (windowed by the rectangular window).
Linear Prediction Order Selection
For computing spectral envelopes via linear prediction, the order ![]() of the predictor should be chosen large enough that the envelope can
follow the contour of the spectrum, but not so large that it follows
the spectral ``fine structure'' on a scale not considered to belong in
the envelope. In particular, for voice,
of the predictor should be chosen large enough that the envelope can
follow the contour of the spectrum, but not so large that it follows
the spectral ``fine structure'' on a scale not considered to belong in
the envelope. In particular, for voice, ![]() should be twice the
number of spectral formants, and perhaps a little larger to
allow more detailed modeling of spectral shape away from the formants.
For a sum of quasi sinusoids, the order
should be twice the
number of spectral formants, and perhaps a little larger to
allow more detailed modeling of spectral shape away from the formants.
For a sum of quasi sinusoids, the order ![]() should be significantly
less than twice the number of sinusoids to inhibit modeling the
sinusoids as spectral-envelope peaks. For filtered-white-noise,
should be significantly
less than twice the number of sinusoids to inhibit modeling the
sinusoids as spectral-envelope peaks. For filtered-white-noise, ![]() should be close to the order of the filter applied to the white noise,
and so on.
should be close to the order of the filter applied to the white noise,
and so on.
Summary of LP Spectral Envelopes
In summary, the spectral envelope of the ![]() th spectral frame,
computed by linear prediction, is given by
th spectral frame,
computed by linear prediction, is given by
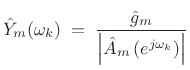 |
(11.13) |
where
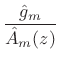 |
(11.14) |
can be driven by unit-variance white noise to produce a filtered-white-noise signal having spectral envelope
It bears repeating that
![]() is zero mean when
is zero mean when
![]() is monic and minimum phase (all zeros inside the unit circle).
This means, for example, that
is monic and minimum phase (all zeros inside the unit circle).
This means, for example, that
![]() can be simply estimated as
the mean of the log spectral magnitude
can be simply estimated as
the mean of the log spectral magnitude
![]() .
.
For best results, the frequency axis ``seen'' by linear prediction should be warped to an auditory frequency scale, as discussed in Appendix E [123]. This has the effect of increasing the accuracy of low-frequency peaks in the extracted spectral envelope, in accordance with the nonuniform frequency resolution of the inner ear.
Spectral Envelope Examples
This section presents matlab code for computing spectral envelopes by the cepstral and linear prediction methods discussed above. The signal to be modeled is a synthetic ``ah'' vowel (as in ``father'') synthesized using three formants driven by a bandlimited impulse train [128].
Signal Synthesis
% Specify formant resonances for an "ah" [a] vowel: F = [700, 1220, 2600]; % Formant frequencies in Hz B = [130, 70, 160]; % Formant bandwidths in Hz fs = 8192; % Sampling rate in Hz % ("telephone quality" for speed) R = exp(-pi*B/fs); % Pole radii theta = 2*pi*F/fs; % Pole angles poles = R .* exp(j*theta); [B,A] = zp2tf(0,[poles,conj(poles)],1); f0 = 200; % Fundamental frequency in Hz w0T = 2*pi*f0/fs; nharm = floor((fs/2)/f0); % number of harmonics nsamps = fs; % make a second's worth sig = zeros(1,nsamps); n = 0:(nsamps-1); % Synthesize bandlimited impulse train: for i=1:nharm, sig = sig + cos(i*w0T*n); end; sig = sig/max(sig); soundsc(sig,fs); % Let's hear it % Now compute the speech vowel: speech = filter(1,A,sig); soundsc([sig,speech],fs); % "buzz", "ahh" % (it would sound much better with a little vibrato)
The Hamming-windowed bandlimited impulse train sig and its spectrum are plotted in Fig.10.1.
![\includegraphics[width=\textwidth ]{eps/ImpulseTrain}](http://www.dsprelated.com/josimages_new/sasp2/img1783.png)
Figure 10.2 shows the Hamming-windowed synthesized vowel speech, and its spectrum overlaid with the true formant envelope.
![\includegraphics[width=\textwidth ]{eps/Speech}](http://www.dsprelated.com/josimages_new/sasp2/img1784.png)
Spectral Envelope by the Cepstral Windowing Method
We now compute the log-magnitude spectrum, perform an inverse FFT to obtain the real cepstrum, lowpass-window the cepstrum, and perform the FFT to obtain the smoothed log-magnitude spectrum:
Nframe = 2^nextpow2(fs/25); % frame size = 40 ms w = hamming(Nframe)'; winspeech = w .* speech(1:Nframe); Nfft = 4*Nframe; % factor of 4 zero-padding sspec = fft(winspeech,Nfft); dbsspecfull = 20*log(abs(sspec)); rcep = ifft(dbsspecfull); % real cepstrum rcep = real(rcep); % eliminate round-off noise in imag part period = round(fs/f0) % 41 nspec = Nfft/2+1; aliasing = norm(rcep(nspec-10:nspec+10))/norm(rcep) % 0.02 nw = 2*period-4; % almost 1 period left and right if floor(nw/2) == nw/2, nw=nw-1; end; % make it odd w = boxcar(nw)'; % rectangular window wzp = [w(((nw+1)/2):nw),zeros(1,Nfft-nw), ... w(1:(nw-1)/2)]; % zero-phase version wrcep = wzp .* rcep; % window the cepstrum ("lifter") rcepenv = fft(wrcep); % spectral envelope rcepenvp = real(rcepenv(1:nspec)); % should be real rcepenvp = rcepenvp - mean(rcepenvp); % normalize to zero mean
Figure 10.3 shows the real cepstrum of the synthetic ``ah'' vowel (top) and the same cepstrum truncated to just under a period in length. In theory, this leaves only formant envelope information in the cepstrum. Figure 10.4 shows an overlay of the spectrum, true envelope, and cepstral envelope.
![\includegraphics[width=\textwidth ]{eps/CepstrumBoxcar}](http://www.dsprelated.com/josimages_new/sasp2/img1785.png)
![\includegraphics[width=\textwidth ]{eps/CepstrumEnvBoxcarC}](http://www.dsprelated.com/josimages_new/sasp2/img1786.png)
Instead of simply truncating the cepstrum (a rectangular windowing operation), we can window it more gracefully. Figure 10.5 shows the result of using a Hann window of the same length. The spectral envelope is smoother as a result.
![\includegraphics[width=\textwidth ]{eps/CepstrumEnvHanningC}](http://www.dsprelated.com/josimages_new/sasp2/img1787.png)
Spectral Envelope by Linear Prediction
Finally, let's do an LPC window. It had better be good because the LPC model is exact for this example.
M = 6; % Assume three formants and no noise % compute Mth-order autocorrelation function: rx = zeros(1,M+1)'; for i=1:M+1, rx(i) = rx(i) + speech(1:nsamps-i+1) ... * speech(1+i-1:nsamps)'; end % prepare the M by M Toeplitz covariance matrix: covmatrix = zeros(M,M); for i=1:M, covmatrix(i,i:M) = rx(1:M-i+1)'; covmatrix(i:M,i) = rx(1:M-i+1); end % solve "normal equations" for prediction coeffs: Acoeffs = - covmatrix \ rx(2:M+1) Alp = [1,Acoeffs']; % LP polynomial A(z) dbenvlp = 20*log10(abs(freqz(1,Alp,nspec)')); dbsspecn = dbsspec + ones(1,nspec)*(max(dbenvlp) ... - max(dbsspec)); % normalize plot(f,[max(dbsspecn,-100);dbenv;dbenvlp]); grid;
![\includegraphics[width=\textwidth ]{eps/LinearPredictionEnvC}](http://www.dsprelated.com/josimages_new/sasp2/img1788.png)
Linear Prediction in Matlab and Octave
In the above example, we implemented essentially the covariance method of LP directly (the autocorrelation estimate was unbiased). The code should run in either Octave or Matlab with the Signal Processing Toolbox.
The Matlab Signal Processing Toolbox has the function lpc available. (LPC stands for ``Linear Predictive Coding.'')
The Octave-Forge lpc function (version 20071212) is a wrapper
for the lattice function which implements Burg's method by
default. Burg's method has the advantage of guaranteeing stability
(![]() is minimum phase) while yielding accuracy comparable to the
covariance method. By uncommenting lines in lpc.m, one can
instead use the ``geometric lattice'' or classic autocorrelation
method (called ``Yule-Walker'' in lpc.m). For details,
``type lpc''.
is minimum phase) while yielding accuracy comparable to the
covariance method. By uncommenting lines in lpc.m, one can
instead use the ``geometric lattice'' or classic autocorrelation
method (called ``Yule-Walker'' in lpc.m). For details,
``type lpc''.
Next Section:
Spectral Modeling Synthesis
Previous Section:
Cross-Synthesis






