



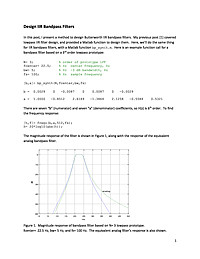
Design IIR Bandpass Filters
In this post, I present a method to design Butterworth IIR bandpass filters. My previous post [1] covered lowpass IIR filter design, and provided a Matlab function to design them. Here, we'll do the same thing for IIR bandpass filters, with a Matlab function bp_synth.m
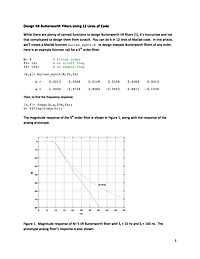
Design IIR Butterworth Filters Using 12 Lines of Code
While there are plenty of canned functions to design Butterworth IIR filters [1], it's instructive and not that complicated to design them from scratch. You can do it in 12 lines of Matlab code.

Algorithms, Architectures, and Applications for Compressive Video Sensing
The design of conventional sensors is based primarily on the Shannon-Nyquist sampling theorem, which states that a signal of bandwidth W Hz is fully determined by its discrete-time samples provided the sampling rate exceeds 2W samples per second. For discrete-time signals, the Shannon-Nyquist theorem has a very simple interpretation: the number of data samples must be at least as large as the dimensionality of the signal being sampled and recovered. This important result enables signal processing in the discrete-time domain without any loss of information. However, in an increasing number of applications, the Shannon-Nyquist sampling theorem dictates an unnecessary and often prohibitively high sampling rate. (See Box 1 for a derivation of the Nyquist rate of a time-varying scene.) As a motivating example, the high resolution of the image sensor hardware in modern cameras reflects the large amount of data sensed to capture an image. A 10-megapixel camera, in effect, takes 10 million measurements of the scene. Yet, almost immediately after acquisition, redundancies in the image are exploited to compress the acquired data significantly, often at compression ratios of 100:1 for visualization and even higher for detection and classification tasks. This example suggests immense wastage in the overall design of conventional cameras.

The Art of VA Filter Design
The book covers the theoretical and practical aspects of the virtual analog filter design in the music DSP context. Only a basic amount of DSP knowledge is assumed as a prerequisite. For digital musical instrument and effect developers.

Multirate Systems and Filter Banks
During the last two decades, multirate filter banks have found various applications in many different areas, such as speech coding, scrambling, adaptive signal processing, image compression, signal and image processing applications as well as transmission of several signals through the same channel. The main idea of using multirate filter banks is the ability of the system to separate in the frequency domain the signal under consideration into two or more signals or to compose two or more different signals into a single signal.

A Review of Physical and Perceptual Feature Extraction Techniques for Speech, Music and Environmental Sounds
Endowing machines with sensing capabilities similar to those of humans is a prevalent quest in engineering and computer science. In the pursuit of making computers sense their surroundings, a huge effort has been conducted to allow machines and computers to acquire, process, analyze and understand their environment in a human-like way. Focusing on the sense of hearing, the ability of computers to sense their acoustic environment as humans do goes by the name of machine hearing. To achieve this ambitious aim, the representation of the audio signal is of paramount importance. In this paper, we present an up-to-date review of the most relevant audio feature extraction techniques developed to analyze the most usual audio signals: speech, music and environmental sounds. Besides revisiting classic approaches for completeness, we include the latest advances in the field based on new domains of analysis together with novel bio-inspired proposals. These approaches are described following a taxonomy that organizes them according to their physical or perceptual basis, being subsequently divided depending on the domain of computation (time, frequency, wavelet, image-based, cepstral, or other domains). The description of the approaches is accompanied with recent examples of their application to machine hearing related problems.

Peak-to-Average Power Ratio and CCDF
Peak to Average Power Ratio (PAPR) is often used to characterize digitally modulated signals. One example application is setting the level of the signal in a digital modulator. Knowing PAPR allows setting the average power to a level that is just low enough to minimize clipping.

Digital PLL's - Part 2
In Part 1, we found the time response of a 2nd order PLL with a proportional + integral (lead-lag) loop filter. Now let's look at this PLL in the Z-domain.

The Swiss Army Knife of Digital Networks
This article describes a general discrete-signal network that appears, in various forms, inside so many DSP applications.

Digital PLL's -- Part 1
We will use Matlab to model the DPLL in the time and frequency domains (Simulink is also a good tool for modeling a DPLL in the time domain). Part 1 discusses the time domain model; the frequency domain model will be covered in Part 2. The frequency domain model will allow us to calculate the loop filter parameters to give the desired bandwidth and damping, but it is a linear model and cannot predict acquisition behavior. The time domain model can be made almost identical to the gate-level system, and as such, is able to model acquisition.

Computing FFT Twiddle Factors
In this document are two algorithms showing how to compute the individual twiddle factors of an N-point decimation-in-frequency (DIF) and an N-point decimation-in-time (DIT) FFT.

Algorithms for Efficient Computation of Convolution
Convolution is an important mathematical tool in both fields of signal and image processing. It is employed in filtering, denoising, edge detection, correlation, compression, deconvolution, simulation, and in many other applications. Although the concept of convolution is not new, the efficient computation of convolution is still an open topic. As the amount of processed data is constantly increasing, there is considerable request for fast manipulation with huge data. Moreover, there is demand for fast algorithms which can exploit computational power of modern parallel architectures.
The Swiss Army Knife of Digital Networks
This article describes a general discrete-signal network that appears, in various forms, inside so many DSP applications.


Implementation of a Tx/Rx OFDM System in a FPGA
The aim of this project consists in the FPGA design and implementation of a transmitter and receiver (Tx/Rx) multicarrier system such the Orthogonal Frequency Division Multiplexing (OFDM). This Tx/Rx OFDM subsystem is capable to deal with with different M-QAM modulations and is implemented in a digital signal processor (DSP-FPGA). The implementation of the Tx/Rx subsystem has been carried out in a FPGA using both System Generator visual programming running over Matlab/Simulink, and the Xilinx ISE program which uses VHDL language. This project is divided into four chapters, each one with a concrete objective. The first chapter is a brief introduction to the digital signal processor used, a field-programmable gate array (FPGA), and to the VHDL programming language. The second chapter is an overview on OFDM, its main advantages and disadvantages in front of previous systems, and a brief description of the different blocks composing the OFDM system. Chapter three provides the implementation details for each of these blocks, and also there is a brief explanation on the theory behind each of the OFDM blocks to provide a better comprehension on its implementation. The fourth chapter is focused, on the one hand, in showing the results of the Matlab/Simulink simulations for the different simulation schemes used and, on the other hand, to show the experimental results obtained using the FPGA to generate the OFDM signal at baseband and then upconverted at the frequency of 3,5 GHz. Finally the conclusions regarding the whole Tx/Rx design and implementation of the OFDM subsystem are given.


C++ Tutorial
This tutorial is for those people who want to learn programming in C++ and do not necessarily have any previous knowledge of other programming languages. Of course any knowledge of other programming languages or any general computer skill can be useful to better understand this tutorial, although it is not essential. It is also suitable for those who need a little update on the new features the language has acquired from the latest standards. If you are familiar with the C language, you can take the first 3 parts of this tutorial as a review of concepts, since they mainly explain the C part of C++. There are slight differences in the C++ syntax for some C features, so I recommend you its reading anyway. The 4th part describes object-oriented programming. The 5th part mostly describes the new features introduced by ANSI-C++ standard.

Zero-Order-Hold function as a model for DAConverters
The output of a digital to analog converter, short DAC, is a constant analog signal between two discrete samples. The DAC's output register retains its value from one sample up to the next sample. The network, which converts the binary value of the register into an analog voltage thus supplies a constant voltage and that leads to a stepped output signal. The analog smoothing filter connected at the output together with the frequency response of the DAC, modeled with a Zero-Order-Hold function, results in distortions. These are examined here and solutions to compensate for them are presented.

Complex Digital Signal Processing in Telecommunications
Digital Signal Processing (DSP) is a vital tool for scientists and engineers, as it is of fundamental importance in many areas of engineering practice and scientific research. The "alphabet" of DSP is mathematics and although most practical DSP problems can be solved by using real number mathematics, there are many others which can only be satisfactorily resolved or adequately described by means of complex numbers. If real number mathematics is the language of real DSP, then complex number mathematics is the language of complex DSP. In the same way that real numbers are a part of complex numbers in mathematics, real DSP can be regarded as a part of complex DSP (Smith, 1999). Complex mathematics manipulates complex numbers - the representation of two variables as a single number - and it may appear that complex DSP has no obvious connection with our everyday experience, especially since many DSP problems are explained mainly by means of real number mathematics. Nonetheless, some DSP techniques are based on complex mathematics, such as Fast Fourier Transform (FFT), z-transform, representation of periodical signals and linear systems, etc. However, the imaginary part of complex transformations is usually ignored or regarded as zero due to the inability to provide a readily comprehensible physical explanation. One well-known practical approach to the representation of an engineering problem by means of complex numbers can be referred to as the assembling approach: the real and imaginary parts of a complex number are real variables and individually can represent two real physical parameters. Complex math techniques are used to process this complex entity once it is assembled. The real and imaginary parts of the resulting complex variable preserve the same real physical parameters. This approach is not universally-applicable and can only be used with problems and applications which conform to the requirements of complex math techniques. Making a complex number entirely mathematically equivalent to a substantial physical problem is the real essence of complex DSP. Like complex Fourier transforms, complex DSP transforms show the fundamental nature of complex DSP and such complex techniques often increase the power of basic DSP methods. The development and application of complex DSP are only just beginning to increase and for this reason some researchers have named it theoretical DSP. It is evident that complex DSP is more complicated than real DSP. Complex DSP transforms are highly theoretical and mathematical; to use them efficiently and professionally requires a large amount of mathematics study and practical experience. Complex math makes the mathematical expressions used in DSP more compact and solves the problems which real math cannot deal with. Complex DSP techniques can complement our understanding of how physical systems perform but to achieve this, we are faced with the necessity of dealing with extensive sophisticated mathematics. For DSP professionals there comes a point at which they have no real choice since the study of complex number mathematics is the foundation of DSP.
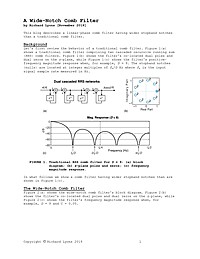
A Wide-Notch Comb Filter
This article describes a linear-phase comb filter having wider stopband notches than a traditional comb filter.





